Advanced Performance
One of the first questions people ask when considering React for a project is whether their application will be as fast and responsive as an equivalent non-React version. The idea of re-rendering an entire subtree of components in response to every state change makes people wonder whether this process negatively impacts performance. React uses several clever techniques to minimize the number of costly DOM operations required to update the UI.
Use the production build #
If you're benchmarking or seeing performance problems in your React apps, make sure you're testing with the minified production build. The development build includes extra warnings that are helpful when building your apps, but it is slower due to the extra bookkeeping it does.
Avoiding reconciling the DOM #
React makes use of a virtual DOM, which is a descriptor of a DOM subtree rendered in the browser. This parallel representation allows React to avoid creating DOM nodes and accessing existing ones, which is slower than operations on JavaScript objects. When a component's props or state change, React decides whether an actual DOM update is necessary by constructing a new virtual DOM and comparing it to the old one. Only in the case they are not equal, will React reconcile the DOM, applying as few mutations as possible.
On top of this, React provides a component lifecycle function, shouldComponentUpdate, which is triggered before the re-rendering process starts (virtual DOM comparison and possible eventual DOM reconciliation), giving the developer the ability to short circuit this process. The default implementation of this function returns true, leaving React to perform the update:
shouldComponentUpdate: function(nextProps, nextState) {
return true;
}
Keep in mind that React will invoke this function pretty often, so the implementation has to be fast.
Say you have a messaging application with several chat threads. Suppose only one of the threads has changed. If we implement shouldComponentUpdate on the ChatThread component, React can skip the rendering step for the other threads:
shouldComponentUpdate: function(nextProps, nextState) {
// TODO: return whether or not current chat thread is
// different to former one.
}
So, in summary, React avoids carrying out expensive DOM operations required to reconcile subtrees of the DOM by allowing the user to short circuit the process using shouldComponentUpdate, and, for those which should update, by comparing virtual DOMs.
shouldComponentUpdate in action #
Here's a subtree of components. For each one is indicated what shouldComponentUpdate returned and whether or not the virtual DOMs were equivalent. Finally, the circle's color indicates whether the component had to be reconciled or not.
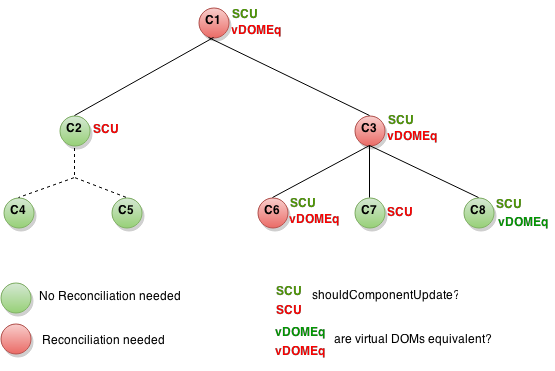
In the example above, since shouldComponentUpdate returned false for the subtree rooted at C2, React had no need to generate the new virtual DOM, and therefore, it neither needed to reconcile the DOM. Note that React didn't even have to invoke shouldComponentUpdate on C4 and C5.
For C1 and C3 shouldComponentUpdate returned true, so React had to go down to the leaves and check them. For C6 it returned true; since the virtual DOMs weren't equivalent it had to reconcile the DOM.
The last interesting case is C8. For this node React had to compute the virtual DOM, but since it was equal to the old one, it didn't have to reconcile it's DOM.
Note that React only had to do DOM mutations for C6, which was inevitable. For C8, it bailed out by comparing the virtual DOMs, and for C2's subtree and C7, it didn't even have to compute the virtual DOM as we bailed out on shouldComponentUpdate.
So, how should we implement shouldComponentUpdate? Say that you have a component that just renders a string value:
React.createClass({
propTypes: {
value: React.PropTypes.string.isRequired
},
render: function() {
return <div>{this.props.value}</div>;
}
});
We could easily implement shouldComponentUpdate as follows:
shouldComponentUpdate: function(nextProps, nextState) {
return this.props.value !== nextProps.value;
}
So far so good, dealing with such simple props/state structures is easy. We could even generalize an implementation based on shallow equality and mix it into components. In fact, React already provides such implementation: PureRenderMixin.
But what if your components' props or state are mutable data structures? Say the prop the component receives, instead of being a string like 'bar', is a JavaScript object that contains a string such as, { foo: 'bar' }:
React.createClass({
propTypes: {
value: React.PropTypes.object.isRequired
},
render: function() {
return <div>{this.props.value.foo}</div>;
}
});
The implementation of shouldComponentUpdate we had before wouldn't always work as expected:
// assume this.props.value is { foo: 'bar' }
// assume nextProps.value is { foo: 'bar' },
// but this reference is different to this.props.value
this.props.value !== nextProps.value; // true
The problem is shouldComponentUpdate will return true when the prop actually didn't change. To fix this, we could come up with this alternative implementation:
shouldComponentUpdate: function(nextProps, nextState) {
return this.props.value.foo !== nextProps.value.foo;
}
Basically, we ended up doing a deep comparison to make sure we properly track changes. In terms of performance, this approach is pretty expensive. It doesn't scale as we would have to write different deep equality code for each model. On top of that, it might not even work if we don't carefully manage object references. Say this component is used by a parent:
React.createClass({
getInitialState: function() {
return { value: { foo: 'bar' } };
},
onClick: function() {
var value = this.state.value;
value.foo += 'bar'; // ANTI-PATTERN!
this.setState({ value: value });
},
render: function() {
return (
<div>
<InnerComponent value={this.state.value} />
<a onClick={this.onClick}>Click me</a>
</div>
);
}
});
The first time the inner component gets rendered, it will have { foo: 'bar' } as the value prop. If the user clicks on the anchor, the parent component's state will get updated to { value: { foo: 'barbar' } }, triggering the re-rendering process of the inner component, which will receive { foo: 'barbar' } as the new value for the prop.
The problem is that since the parent and inner components share a reference to the same object, when the object gets mutated on line 2 of the onClick function, the prop the inner component had will change. So, when the re-rendering process starts, and shouldComponentUpdate gets invoked, this.props.value.foo will be equal to nextProps.value.foo, because in fact, this.props.value references the same object as nextProps.value.
Consequently, since we'll miss the change on the prop and short circuit the re-rendering process, the UI won't get updated from 'bar' to 'barbar'.
Immutable-js to the rescue #
Immutable-js is a JavaScript collections library written by Lee Byron, which Facebook recently open-sourced. It provides immutable persistent collections via structural sharing. Let's see what these properties mean:
- Immutable: once created, a collection cannot be altered at another point in time.
- Persistent: new collections can be created from a previous collection and a mutation such as set. The original collection is still valid after the new collection is created.
- Structural Sharing: new collections are created using as much of the same structure as the original collection as possible, reducing copying to a minimum to achieve space efficiency and acceptable performance. If the new collection is equal to the original, the original is often returned.
Immutability makes tracking changes cheap; a change will always result in a new object so we only need to check if the reference to the object has changed. For example, in this regular JavaScript code:
var x = { foo: "bar" };
var y = x;
y.foo = "baz";
x === y; // true
Although y was edited, since it's a reference to the same object as x, this comparison returns true. However, this code could be written using immutable-js as follows:
var SomeRecord = Immutable.Record({ foo: null });
var x = new SomeRecord({ foo: 'bar' });
var y = x.set('foo', 'baz');
x === y; // false
In this case, since a new reference is returned when mutating x, we can safely assume that x has changed.
Another possible way to track changes could be doing dirty checking by having a flag set by setters. A problem with this approach is that it forces you to use setters and, either write a lot of additional code, or somehow instrument your classes. Alternatively, you could deep copy the object just before the mutations and deep compare to determine whether there was a change or not. A problem with this approach is both deepCopy and deepCompare are expensive operations.
So, Immutable data structures provides you a cheap and less verbose way to track changes on objects, which is all we need to implement shouldComponentUpdate. Therefore, if we model props and state attributes using the abstractions provided by immutable-js we'll be able to use PureRenderMixin and get a nice boost in perf.
Immutable-js and Flux #
If you're using Flux, you should start writing your stores using immutable-js. Take a look at the full API.
Let's see one possible way to model the thread example using Immutable data structures. First, we need to define a Record for each of the entities we're trying to model. Records are just immutable containers that hold values for a specific set of fields:
var User = Immutable.Record({
id: undefined,
name: undefined,
email: undefined
});
var Message = Immutable.Record({
timestamp: new Date(),
sender: undefined,
text: ''
});
The Record function receives an object that defines the fields the object has and its default values.
The messages store could keep track of the users and messages using two lists:
this.users = Immutable.List();
this.messages = Immutable.List();
It should be pretty straightforward to implement functions to process each payload type. For instance, when the store sees a payload representing a new message, we can just create a new record and append it to the messages list:
this.messages = this.messages.push(new Message({
timestamp: payload.timestamp,
sender: payload.sender,
text: payload.text
});
Note that since the data structures are immutable, we need to assign the result of the push function to this.messages.
On the React side, if we also use immutable-js data structures to hold the components' state, we could mix PureRenderMixin into all our components and short circuit the re-rendering process.